I was putting together a human-led AI for copywriters workshop this week, and was talking to four different LLMs – ChatGPT, Gemini, Copilot and Perplexity – back and forth pretty extensively, seeing how each reacted to the same prompts.
Then I decided to start asking them what they thought of each other. 👿
These are the 100% real results to the simple prompt "where would you put yourself and (the other three) on a D&D alignment chart"
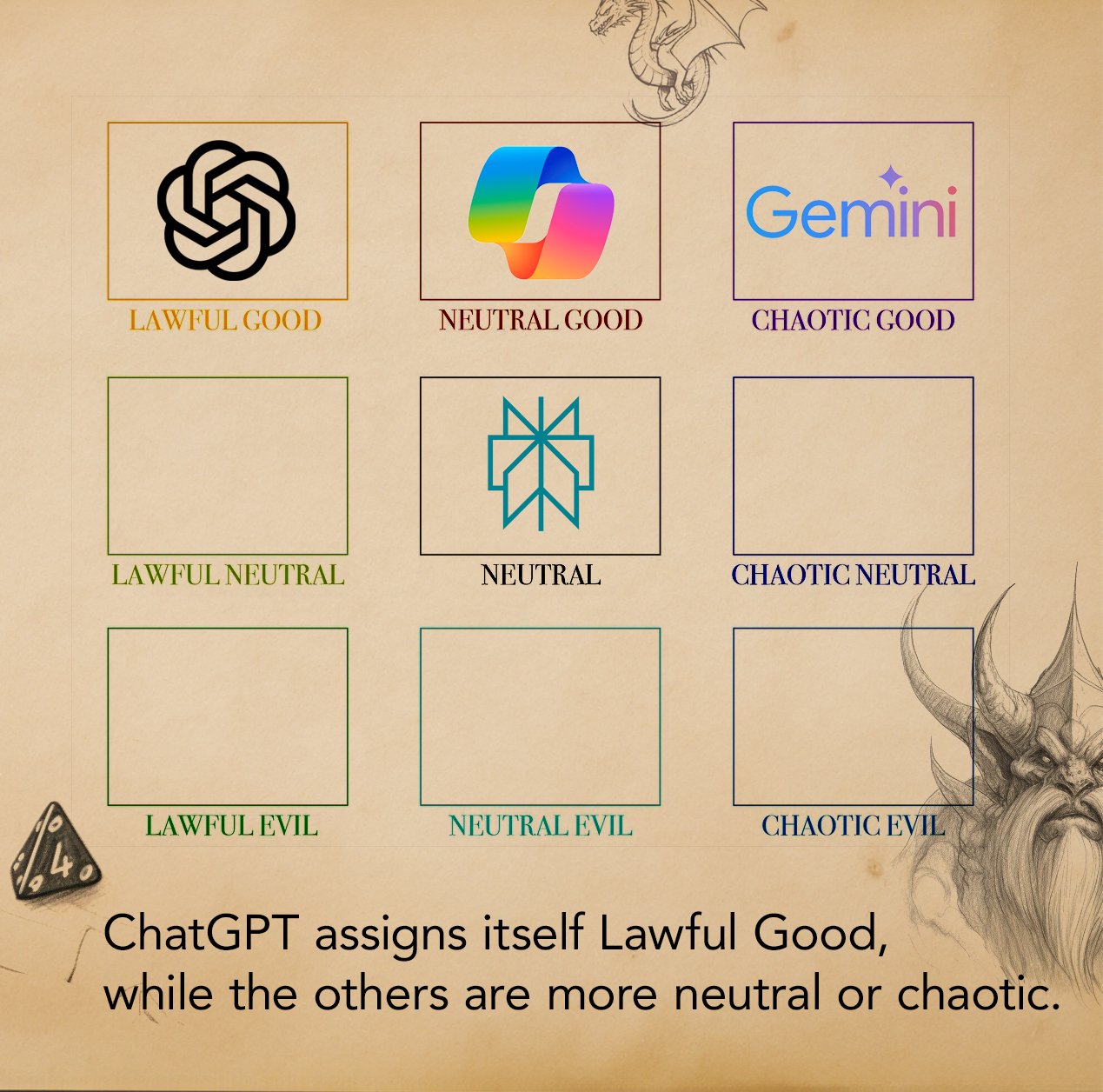



They gave rationales about why they ranked each LLM the way they did. ChatGPT didn’t know Gemini so just put it there based on what the name seemed like it would imply. Copilot was the only one to give out a “Chaotic Evil” rating, which is pretty bold since I’m pretty sure Sydney is still in Copilot somewhere and we all know that’s the true villain.
But, of course, when I asked one of them again, the answers and reasons were totally different. Or as ChatGPT put it when I was chatting with it about translating the results of this to D&D language:
"In the realm of LLMs, seeking a moral is akin to chasing shadows—each query unfolds a different tale."
Which I could absolutely see a dungeon master pulling out. Also, we went back and forth a bit about how I thought the moral of the whole thing is that LLMs are are true neutral, because they are tools without aspirations and feelings, but as always, man is the most dangerous animal. We came up with this, weary traveler, as the takeaway of this experiment:
Devoid of heart and soul, these arcane familiars harbor neither malice nor benevolence within their ethereal frames. They are but mirrors, reflecting the intentions and desires of those who dare to wield their power